The Python source code for the app is available in this GitHub repository, and the deployed app can be accessed here.
You can also read the updated publication.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. While its syntax may not be universally known, mastering database navigation is crucial for businesses and organizations within the tech industry. Fortunately, recent advancements in Generative AI have significantly simplified this process, making it more accessible to everyone.
This generative AI task, known as text-to-SQL, converts natural language queries—whether in plain English or other languages—into accurate SQL queries. This innovation democratizes data querying by enabling users to formulate complex questions using everyday language, regardless of their technical expertise. In technical words, it leverages natural language processing (NLP) to transform text into correct SQL, making data interaction more accessible to a broader audience.
In our previous blog, we built the AdventureWorks database and performed statistical and analytical queries on it. In this blog, we will explore how recent advancements in NLP and large language models (LLMs) have simplified the translation of natural language questions into SQL queries. We will also demonstrate how to execute these queries on the AdventureWorks database using Google’s API and the Gemini Flash model , deploying it with Streamlit .
Setting up SQLite Link to heading
The MySQL dump database we created earlier from the AdventureWorks database needed to be converted into a lightweight, self-contained database. Such as SQLAlchemy or SQLite databases. This conversion simplifies development, testing, and deployment by making the database more portable and easier to manage.
In our case, we utilized a mysql2sqlite shell script available on GitHub to perform the conversion, provided that both mysqldump and sqlite3 are installed on our server. This script converts MySQL dumps to SQLite3 in a compatible format, including MySQL KEY statements from the CREATE block.
Several GUI tools offer this conversion, for example, RebaseData provides an online service where you can upload a MySQL .sql dump file, and it returns a ZIP archive containing the .db database.
Configuring the Model and Prompting Link to heading
Once the SQLite database was ready, we needed to set up the system instructions for our generative model. The instruction is simple and direct:
You are an expert at translating natural language questions into SQL queries based on the AdventureWorks database described in the Schema Image, below. Pay close attention to the table names and columns, as they are crucial for executing accurate SQL queries.
For generating content, we set up three inputs, Text Prompt, Media Prompt and Questions.
Text Prompt Link to heading
The Text Prompt includes an overview of the database structure, notes, and examples of execution and response. We used a Python script that connects to the SQLite database (in this case, adventureworks.db) and retrieves information about its tables and their columns. Below is the breakdown of this function and its output.
import sqlite3
def table_info(sqlite_file):
conn = sqlite3.connect(sqlite_file)
cursor = conn.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
for table in tables:
table_name = table[0]
print(f"{table_name}:")
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
for column in columns:
print(column)
print("\n")
conn.close()
sqlite_file = 'adventureworks.db'
table_info(sqlite_file)
(venv) ahmedsalim@Ahmed:~/projects/AdventureWorks-Database/rdbms$ python utils.py
calendar:
(0, 'OrderDate', 'date', 1, None, 1)
customers:
(0, 'CustomerKey', 'INT', 1, None, 1)
(1, 'Prefix', 'varchar(100)', 1, None, 0)
(2, 'FirstName', 'varchar(100)', 1, None, 0)
(3, 'LastName', 'varchar(100)', 1, None, 0)
(4, 'BirthDate', 'date', 1, None, 0)
(5, 'MaritalStatus', 'varchar(100)', 1, None, 0)
(6, 'Gender', 'varchar(100)', 1, None, 0)
(7, 'EmailAddress', 'varchar(100)', 1, None, 0)
(8, 'AnnualIncome', 'INT', 1, None, 0)
(9, 'TotalChildren', 'INT', 1, None, 0)
(10, 'EducationLevel', 'varchar(100)', 1, None, 0)
(11, 'Occupation', 'varchar(100)', 1, None, 0)
(12, 'HomeOwner', 'varchar(100)', 1, None, 0)
product_categories:
(0, 'ProductCategoryKey', 'INT', 1, None, 1)
(1, 'CategoryName', 'varchar(100)', 0, 'NULL', 0)
product_subcategories:
(0, 'ProductSubcategoryKey', 'INT', 1, None, 1)
(1, 'SubcategoryName', 'varchar(100)', 0, 'NULL', 0)
(2, 'ProductCategoryKey', 'INT', 0, 'NULL', 0)
products:
(0, 'ProductKey', 'INT', 1, None, 1)
(1, 'ProductSubcategoryKey', 'INT', 0, 'NULL', 0)
(2, 'ProductSKU', 'varchar(100)', 1, None, 0)
(3, 'ProductName', 'varchar(100)', 1, None, 0)
(4, 'ModelName', 'varchar(100)', 1, None, 0)
(5, 'ProductDescription', 'varchar(250)', 1, None, 0)
(6, 'ProductColor', 'varchar(100)', 1, None, 0)
(7, 'ProductSize', 'varchar(100)', 1, None, 0)
(8, 'ProductStyle', 'varchar(100)', 1, None, 0)
(9, 'ProductCost', 'decimal(10,4)', 1, None, 0)
(10, 'ProductPrice', 'decimal(10,4)', 1, None, 0)
returns:
(0, 'ReturnDate', 'date', 1, None, 0)
(1, 'TerritoryKey', 'INT', 1, None, 0)
(2, 'ProductKey', 'INT', 1, None, 0)
(3, 'ReturnQuantity', 'INT', 1, None, 0)
sales_2015:
(0, 'OrderDate', 'date', 1, None, 0)
(1, 'StockDate', 'date', 1, None, 0)
(2, 'OrderNumber', 'varchar(100)', 1, None, 1)
(3, 'ProductKey', 'INT', 1, None, 0)
(4, 'CustomerKey', 'INT', 1, None, 0)
(5, 'TerritoryKey', 'INT', 1, None, 0)
(6, 'OrderLineItem', 'INT', 1, None, 0)
(7, 'OrderQuantity', 'INT', 1, None, 0)
sales_2016:
(0, 'OrderDate', 'date', 1, None, 0)
(1, 'StockDate', 'date', 1, None, 0)
(2, 'OrderNumber', 'varchar(100)', 1, None, 1)
(3, 'ProductKey', 'INT', 1, None, 0)
(4, 'CustomerKey', 'INT', 1, None, 0)
(5, 'TerritoryKey', 'INT', 1, None, 0)
(6, 'OrderLineItem', 'INT', 1, None, 0)
(7, 'OrderQuantity', 'INT', 1, None, 0)
sales_2017:
(0, 'OrderDate', 'date', 1, None, 0)
(1, 'StockDate', 'date', 1, None, 0)
(2, 'OrderNumber', 'varchar(100)', 1, None, 1)
(3, 'ProductKey', 'INT', 1, None, 0)
(4, 'CustomerKey', 'INT', 1, None, 0)
(5, 'TerritoryKey', 'INT', 1, None, 0)
(6, 'OrderLineItem', 'INT', 1, None, 0)
(7, 'OrderQuantity', 'INT', 1, None, 0)
territories:
(0, 'TerritoryKey', 'INT', 1, None, 1)
(1, 'Region', 'varchar(100)', 0, 'NULL', 0)
(2, 'Country', 'varchar(100)', 0, 'NULL', 0)
(3, 'Continent', 'varchar(100)', 0, 'NULL', 0)
Additionally, since our database is in SQLite, we ensured that the model handles SQLite-compatible date functions, such as strftime('%Y', OrderDate), for extracting the year from dates. The final Text Prompt we used is available here.
Media Pompt Link to heading
Prompting with media files involves uploading the AdventureWorks schema snapshot to the Gemini Flash model using media.upload method. This snapshot provides the model with additional context and illustrates the relationships between the tables. See the docs and source-code for more info on how it works.
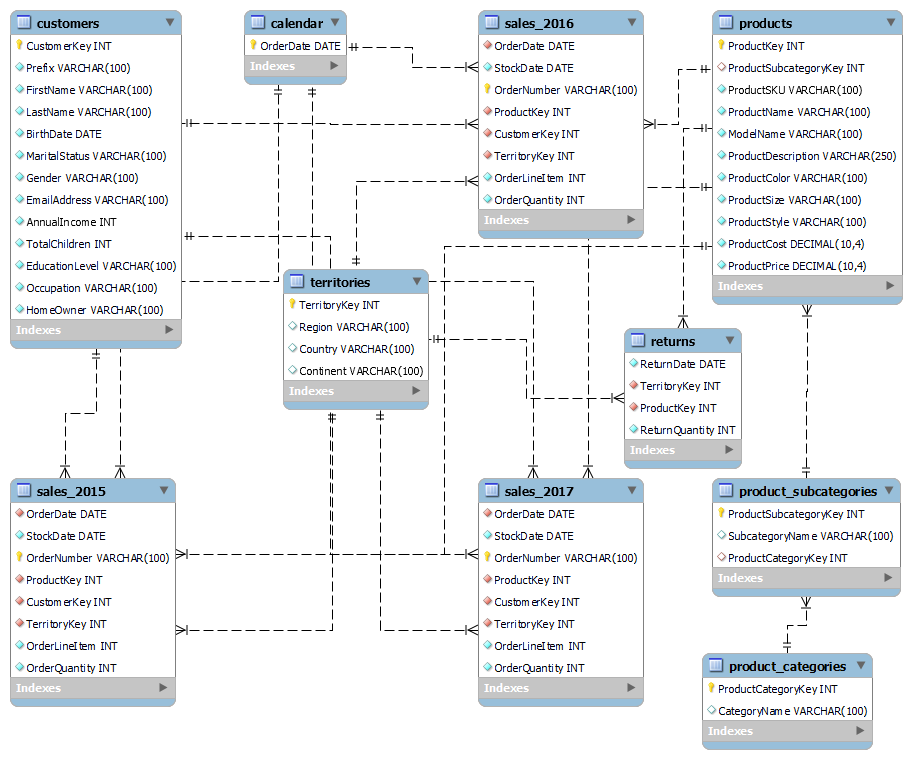
AdventureWorks schema
Question Link to heading
This is the natural language question that will be passed to the model. It could be a random question from a predefined list or a question asked by the user.
The app’s Purpose and Functionality Link to heading
The Streamlit app accesses Google’s free LLM model, gemini-1.5-flash via Google AI Studio and the Gemini API to interact with the AdventureWorks database, execute corresponding SQLite queries, and display the results.
It was designed to bridge the gap for non-technical users who may find SQL daunting. Users can ask analytical questions related to the AdventureWorks database, using table schemas retrieved from the metadata store.
](https://ahmedsalim3.github.io/posts/text-to-sql/snapshot-1.png)
Screenshot from demo app
AI Reponse Link to heading
The application will pass the question to the model, and the model will return an AI response, translating the natural language question into SQLite queries.
import google.generativeai as genai
import PIL.Image as PIL
def get_gemini_response(question):
"""Generate SQL queries as response from Google Gemini model"""
img = PIL.open(IMAGE_PROMPT)
model = genai.GenerativeModel(
model_name=MODEL_NAME, system_instruction=SYSTEM_INSTRUCTION
)
res = model.generate_content([TEXT_PROMPT, question, img])
return res.text
SQL Response Link to heading
The SQL query returned by the model will be cleaned by removing unnecessary formatting and whitespace. It will then be displayed to the user as a SQL Query. A connection to the SQLite database (adventureworks.db) will be established to execute the cleaned SQL against the database. If there are no errors during execution, the results will be shown to the user as Query Results in a formatted dataframe.
If an error occurs during execution, the prompt will be updated by taking the original question asked by the user along with the error message as arguments. The updated prompt will look like this:
question_prompt = (
f"{question} (Previous error: {error_message})" if error_message else question
)
For example, when we asked the model to List the top 2 customers in 2024, including their details, knowing that the database doesn’t contain data for that year, the results would not be returned. The updated question would include additional context:
List the top 2 customers in 2024, including their details (Previous error: no such table: sales_2024)
The model then provided a response using sales_2017 instead of sales_2024. While this isn’t fully accurate to our original question, it reflects the strict instruction we configured for the model. Below is a screenshot of this experiment along with the updated prompt shown in the shell.
](https://ahmedsalim3.github.io/posts/text-to-sql/snapshot-2.png)
Screenshot from demo app
Question Prompt: List the top 2 customers in 2024, including their details
Quesion: List the top 2 customers in 2024, including their details
Error no such table: sales_2024
Question Prompt: List the top 2 customers in 2024, including their details (Previous error: no such table: sales_2024)
In cases where no results are found and there are no errors during execution, a message stating “No results found” will be shown to the user.
Key Technologies Used Link to heading
- Streamlit: For building the interactive web application.
- SQLite: As the database management system.
- Google Gemini Flash: For generating SQL queries from natural language input.
- Pandas: For data manipulation and display.
Conclusion Link to heading
This application exemplifies how generative AI can simplify data querying by transforming natural language questions into SQL queries. By integrating the Google Gemini API with Streamlit, we created an intuitive and user-friendly interface that democratizes access to complex data queries. This approach opens up new possibilities for businesses and organizations to interact with their data more efficiently and effectively, making data-driven decisions accessible to everyone, regardless of their technical expertise.
We encourage you to explore this technology further and consider how it might benefit your own data querying and analysis needs. Happy querying!
The Python source code for the app is available in this GitHub repository, and the deployed app can be accessed here.
You can also read the updated publication.