
What’s Sentiment Analysis? Link to heading
Sentiment analysis is the process of identifying the emotions or opinions expressed in text, speech, or other forms of communication. It’s essentially about linking data to a particular sentiment, which is why it’s also referred to as opinion mining.
You’ve probably seen sentiment analysis in action before, like when a brand tracks social media mentions to understand how people feel about a recent product launch. For example, you might notice a company responding to both positive and negative comments on Facebook, indicating they’re actively monitoring customer sentiment. Similarly, when you’re thinking about buying a product, the first thing you will probabily do is to browse online reviews for that product, you’ll often find ratings or summaries that capture the overall sentiment of other users feedback.
Collecting feedback on a product is one thing, but understanding how users truly feel about the brand is another. This technique is widely used in marketing to determine whether opinions about a brand or product are positive or negative. However, it also has applications in other areas, such as crisis management and politics.
In this blog, we’ll walk you through a step-by-step process for performing sentiment analysis in Python. We will use IMDB movie reviews, using datasets sourced from Andrew Maas at the Stanford AI Lab.
Challenges Link to heading
Sentiment analysis comes with its own set of challenges, but the key challenge lies in understanding complex human emotions. The task of interpreting human emotions involves recognizing subtleties like sarcasm, irony, and sensitivity to context and language skills. These elements are what make human communication rich and meaningful but present challenges when analyzing them through algorithms and machines. For example, take the case of Bic Inc., which launched a pen “designed for women.” A customer’s review on Amazon reads:

Without the rating, this review might sound positive or even confusing, but the sarcasm reveals dissatisfaction with what the customer sees as a gendered product. Quantitative data might miss this entirely, as the richness of human emotions often slips through, leading to potential misinterpretations and missed connections with the audience.
Text Classification Pipeline Link to heading
In our text classification pipeline, we’ll navigate through several steps to accomplish sentiment analysis on IMDB movie reviews. Our approach involves data processing, vectorization, and model building. We will explore traditional machine learning models from scikit-learn to classify movie reviews as either positive or negative.
Step 1: Data Collection and Preparation Link to heading
- The dataset consists of two columns:
reviewandsentiment. - Sentiments are labeled as
posorneg, with each sentiment comprising 25,000 samples. - The review column contains various syntaxes, symbols, and punctuations that need to be pruned off before feeding text data into a machine learning model.
Step 2: Text Preprocessing Link to heading
This step mainly includes cleaning, tokenization, and vectorization on the review column. We remove HTML syntax, URLs, Standardize letter casing, Fix contractions, Remove stopwords, and Remove all non-word characters. Here’s a breakdown of the preprocessing steps:
1. Removing HTML Tags: Link to heading
The review column often contains HTML elements and links that do not contribute to the sentiment analysis. We only want the human-readable text from the review column. To achieve this, we use the get_text() method from the BeautifulSoup library to strip out any HTML tags. This method returns all the text within the review as a single Unicode string.
from bs4 import BeautifulSoup
def clean_html(df):
df['review'] = df['review'].apply(
lambda string: BeautifulSoup(string, 'html.parser').get_text()
)
2. Cleaning URLs: Link to heading
Sometimes people include URLs in their reviews when comparing movies or sharing links, and we want to remove these links from the texts in the review column. We used a custom regular expression to remove these URLs from the review text.
Regex can be tricky in Python, but tools like regex101 make it easy to understand and test. For example, check out this regex101 example to see how the URL pattern is identified and removed using the substitution function.
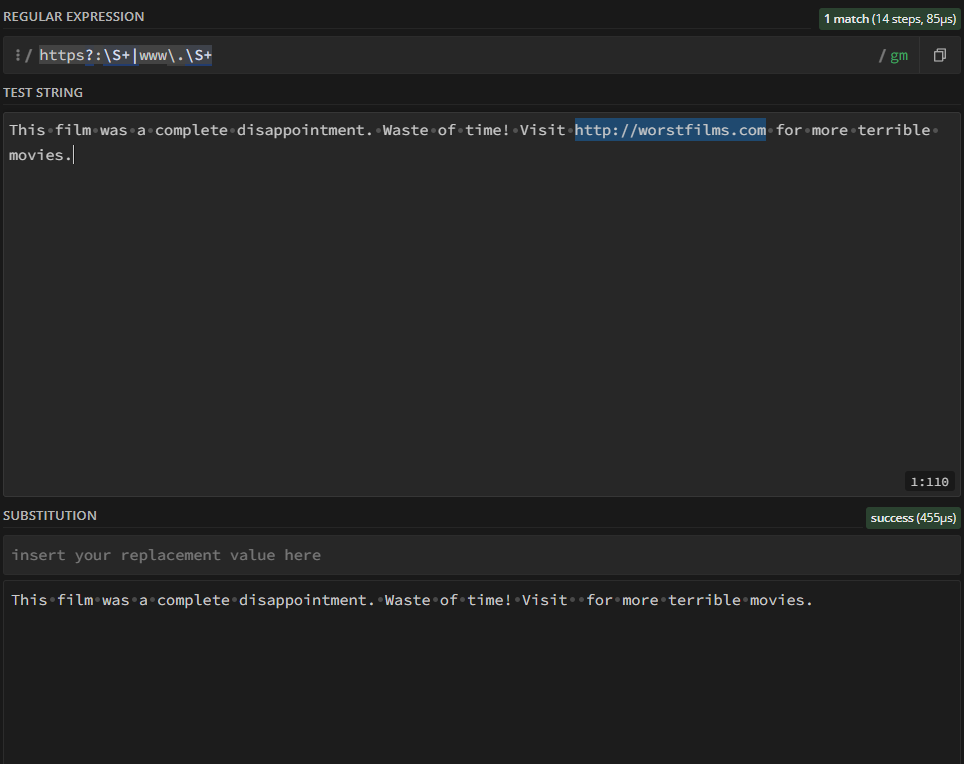
Once you’ve created your regular expression, simply click Code Generator under Tools in the sidebar to generate code for different languages. Here’s the Python function we used after generating the regex:
import re
def clean_url(df):
df['review'] = df['review'].str.replace(
r"https?://\S+|www\.\S+", '', regex=True
)
Note that in Python, the backslash \ is also treated as an escape character in strings. To ensure it’s correctly interpreted in regex patterns, either use a double backslash \\ or a raw string by adding r before the string.
For example, https?://\S+ should be written as r"https?://\S+" to avoid confusion.
3 Standardizing Casing: Link to heading
To make the analysis case-insensitive, we’ll convert all text to lowercase by applying the built-in str.lower()
def standardize_casing(df):
df['review'] = df['review'].str.lower()
return df
4. Replacing Contractions: Link to heading
Contractions are expanded to their full forms, which helps in normalizing the text data and ensuring consistency in word representation. We used regular expressions to expand contractions of a word, following an approach derived from Yaman’s gist
import re
replacement_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
(r'ain\'t', 'is not'),
(r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
(r'(\w+)\'d', '\g<1> would')
]
class RegexpReplacer(object):
def __init__(self, patterns=replacement_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return s
def replace_contractions(df):
replacer = RegexpReplacer(replacement_patterns)
df['review'] = df['review'].apply(lambda x: replacer.replace(x))
return df
5. Removing Stopwords: Link to heading
Apart from the contraction replacement, we also used NLTK to remove stopwords. Stopwords are common words that carry little meaning on their own, such as “is,” “an,” and “the.” By filtering these out, we can focus on the more meaningful components of the data. Follow this guide for more informations about how to use it in Python.
6. Tokenization and Lemmatization Link to heading
Tokenization is the process of splitting text into individual words, or tokens. Lemmatization, on the other hand, converts words to their base or dictionary form (e.g., plays → play).
Tokenization is a crucial step before lemmatization because it allows the algorithm to process each word separately, making the lemmatization more efficient and accurate by focusing on individual tokens rather than the entire text.
Step 3: Text Vectorization Link to heading
Once the text is preprocessed, we need to convert it into a format that machine learning models can understand, numbers. Vectorization transforms the cleaned text into numerical representations, and there are several ways to achieve this. Here, we use two common methods from scikit-learn:
- CountVectorizer: This method counts the occurrence of each word in the dataset and represents the text as a matrix of word counts. Follow this short tutorial for more in depth.
- TfidfVectorizer: The TF-IDF (Term Frequency-Inverse Document Frequency) method scales word counts by how important they are to a document relative to the entire corpus. It gives less weight to commonly used words and more to unique ones, and here is a tutorial to cover that.
You can think of this step as transforming our reviews into a big spreadsheet where each row is a review, and each column is a word. The values in the cells represent how often each word appears in the review.
Before applying vectorization, the normalized dataset is split into X_train, X_test, y_train, and y_test.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
class TextVectorizer:
def __init__(self, stopwords, max_features=5000):
self.tokenizer = CountVectorizer().build_tokenizer()
self.stop_words_tokens = self.tokenizer(" ".join(stopwords))
self.count_vectorizer = CountVectorizer(max_df=0.8, min_df=3, tokenizer=nltk.word_tokenize,
stop_words=stopwords, max_features=max_features)
self.tfidf_vectorizer = TfidfVectorizer(max_df=0.8, min_df=3, tokenizer=nltk.word_tokenize,
stop_words=self.stop_words_tokens, max_features=max_features)
def fit_transform_count(self, X_train):
countvect_train = pd.DataFrame(self.count_vectorizer.fit_transform(X_train).toarray(),
columns=self.count_vectorizer.get_feature_names_out())
return countvect_train
def transform_count(self, x_test):
countvect_test = pd.DataFrame(self.count_vectorizer.transform(x_test).toarray(),
columns=self.count_vectorizer.get_feature_names_out())
return countvect_test
def fit_transform_tfidf(self, x_train):
tfidfvect_train = pd.DataFrame(self.tfidf_vectorizer.fit_transform(x_train).toarray(),
columns=self.tfidf_vectorizer.get_feature_names_out())
return tfidfvect_train
def transform_tfidf(self, x_test):
tfidfvect_test = pd.DataFrame(self.tfidf_vectorizer.transform(x_test).toarray(),
columns=self.tfidf_vectorizer.get_feature_names_out())
return tfidfvect_test
Step 3: Text Classification Link to heading
We trained several classifiers, including Logistic Regression, Random Forest, MLP, Multinomial Naive Bayes, and Gaussian Naive Bayes.
from nltk.corpus import stopwords
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.naive_bayes import MultinomialNB, GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from text_vectorization import TextVectorizer, encode_labels
class TextClassifier:
def __init__(self, cleaned_df, max_features=5000):
self.cleaned_df = cleaned_df
self.vectorizer = TextVectorizer(stopwords.words('english'), max_features=max_features)
self.LogisticRegression = LogisticRegression()
self.MLPClassifier = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(5, 2), random_state=1, max_iter=200)
self.MultinomialNB = MultinomialNB()
self.GaussianNB = GaussianNB()
self.RandomForestClassifier = RandomForestClassifier(n_estimators=1000, random_state=0)
self.DecisionTreeClassifier = DecisionTreeClassifier(random_state=42)
self.X = None
self.y = None
self.X_train = None
self.X_test = None
self.y_train = None
self.y_test = None
self.method = None
self.X_test_vect = None
self.X_train_vect = None
def splitting(self, test_size=0.1):
self.X = self.cleaned_df['lemma_review']
self.y = self.cleaned_df['sentiment']
self.y = encode_labels(self.y)
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size=test_size,
random_state=42)
def transform_data(self, method='CountVectorizer'):
self.method = method
if method == 'CountVectorizer':
self.X_train_vect = self.vectorizer.fit_transform_count(self.X_train)
self.X_test_vect = self.vectorizer.transform_count(self.X_test)
elif method == 'TfidfVectorizer':
self.X_train_vect = self.vectorizer.fit_transform_tfidf(self.X_train)
self.X_test_vect = self.vectorizer.transform_tfidf(self.X_test)
else:
raise ValueError("Method must be 'CountVectorizer' or 'TfidfVectorizer'")
def train_model(self, model='MLPClassifier'):
if model == 'MLPClassifier':
clf = self.MLPClassifier
elif model == 'LogisticRegression':
clf = self.LogisticRegression
elif model == 'MultinomialNB':
clf = self.MultinomialNB
elif model == 'GaussianNB':
clf = self.GaussianNB
elif model == 'RandomForestClassifier':
clf = self.RandomForestClassifier
elif model == 'DecisionTreeClassifier':
clf = self.DecisionTreeClassifier
else:
raise ValueError(
"Model must be 'MLPClassifier','LogisticRegression', 'MultinomialNB', 'GaussianNB', 'RandomForestClassifier', or 'DecisionTreeClassifier'")
clf.fit(self.X_train_vect, self.y_train)
print(f"{'-' * 30}\n Model: {model}\n Method: {self.method}\n{'*' * 30}")
return clf
def evaluate_model(self, clf):
accuracy = clf.score(self.X_test_vect, self.y_test)
print(f'Accuracy: {accuracy:.2f}')
predictions = clf.predict(self.X_test_vect)
print('Classification Report:\n')
print(classification_report(self.y_test, predictions, target_names=['negative', 'positive'], digits=2))
report = classification_report(self.y_test, predictions, target_names=['negative', 'positive'], digits=2,
output_dict=True)
avg_precision = report['weighted avg']['precision']
avg_recall = report['weighted avg']['recall']
avg_f1_score = report['weighted avg']['f1-score']
print(f'Average Precision: {avg_precision:.4f}')
print(f'Average Recall: {avg_recall:.4f}')
print(f'Average F1 Score: {avg_f1_score:.4f}')
return accuracy, report
Results and Findings Link to heading
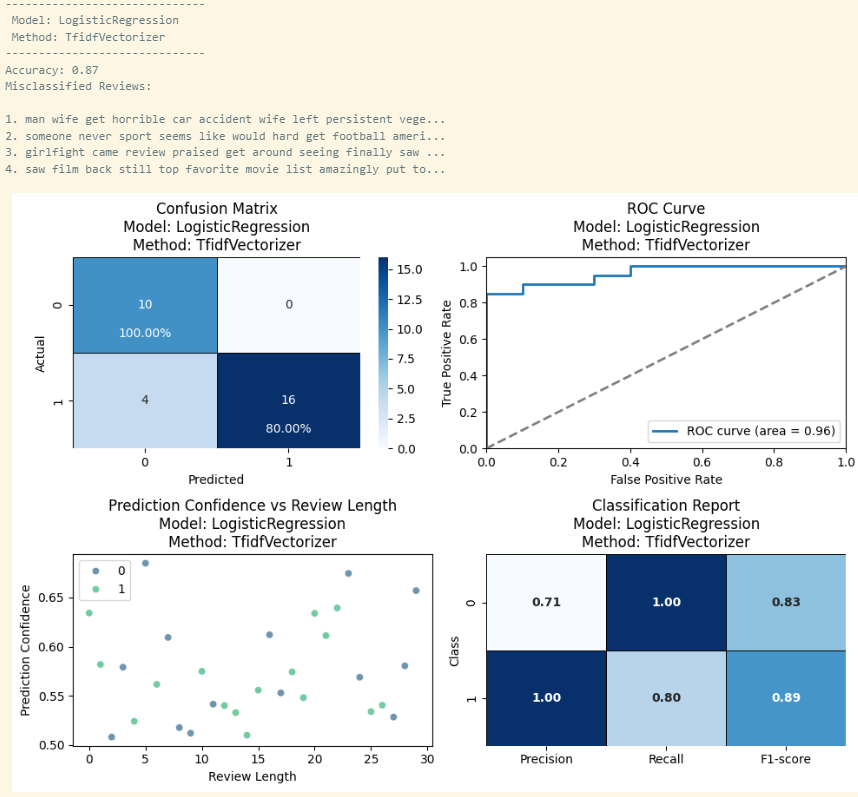
We can use predictive models to predict audience sentiment based on their review comments. Logistic regression is the best-performing model as it has the highest accuracy of 86%, with fairly low training and testing time. TF-IDF outperformed Contvectorizer across all six models
Predicting Sentiment Link to heading
def predict_review_sentiment(review_text):
# Transform the review text using the TF-IDF vectorizer
review_tfidf = t_vect.transform([review_text])
# Predict the sentiment using the trained logistic regression model
sentiment = lr.predict(review_tfidf)
# Return the predicted sentiment (0 for negative, 1 for positive)
if sentiment[0] == 1:
return "positive"
else:
return "negative"
# Example review text
review_text = "This movie was fantastic!!! I enjoyed every minute of it."
# Predict the sentiment of the review
my_review = predict_review_sentiment(review_text)
print(my_review)
positive
Conclusion Link to heading
In this study, we conducted a sentiment analysis of movie reviews from IMDB to predict the sentiment of the audience towards a given movie based on unstructured reviews. Thorough preprocessing involving text normalization and vectorization is needed before model training. Our findings showed that logistic regression was able to accurately predict the sentiment of the reviews with an accuracy of 0.87 using the TF-IDF vectorization method. Common themes and words indicative of positive or negative sentiment are extracted from the model to allow for interpretation.