After creating the Adventure Works relational database, where we applied statistical and analytical SQL queries, we’re now shifting our focus to developing a NoSQL document-based database using MongoDB Compass. We’ll migrate the database and apply similar aggregations in this new context.
To effectively work with MongoDB, it’s important to understand a few key terms:
- Documents: These are akin to records or rows in relational database tables.
- Collections: A collection is a group of documents, similar to a table in a relational database.
- Database: A database in MongoDB stores one or more collections of documents.
For reference, Figure below illustrates the Entity Relationship Diagram (ERD) used in the previous SQL Project.
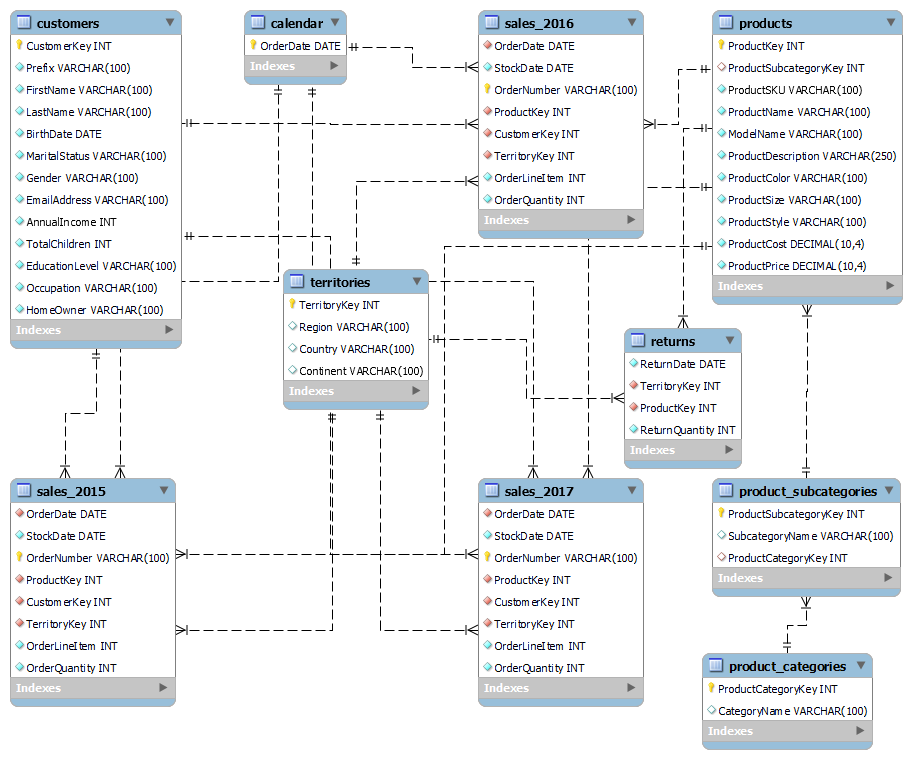
Entity Relationship Diagram
We can see that there are 10 tables. The process of converting these tables from MySQL into MongoDB Compass involves the following steps:
Export Tables: The first step is to export the tables from the adventureworks dump database stored in MySQL Workbench and convert them into JSON format.
Import Data into MongoDB Compass:
- Start by creating a database in MongoDB Compass with the specified name.
- Establish a collection within this database.
- After setting up the database and collection, proceed to import the data in JSON format into the newly created collection.
- Repeat these steps for each collection.
These instructions are illustrated in Figures below.
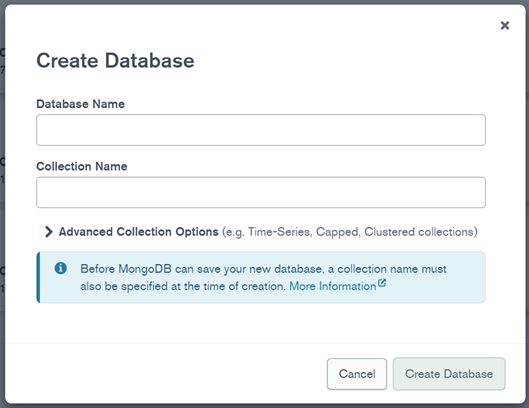
Create Database and Collection in MongoDB Compass
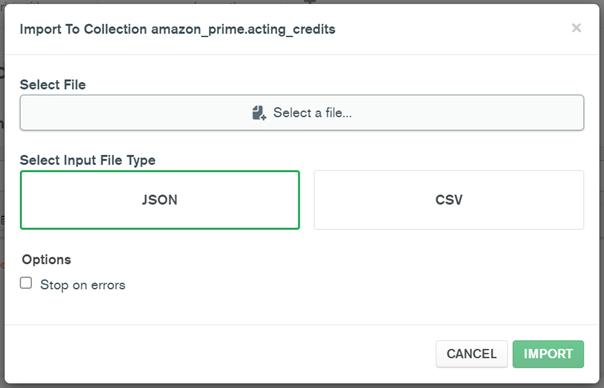
Import .json files into Collections
Document design Link to heading
The choice between embedded and referenced document design in MongoDB Compass depends on the relationships between the tables and the data access patterns in our application.
In general:
- Embedded documents are useful for modeling one-to-many relationships where the related data will always be retrieved together with the parent document.
- Referenced design is useful for modeling many-to-many relationships, where the related data is not always needed. In such cases, references (ObjectIDs) are used to link documents.
However, since we are using the AdventureWorks database from SQL, it seems like a combination of both embedded and referenced document design would be appropriate, based on the relationships between our tables and the data access patterns in our application.
For example:
The tables
sales_2015,sales_2016, andsales_2017have been stored as separate documents in asalescollection and referenced from thecustomersandproductscollections.The tables
products_categories,products_subcategories, andproductswere embedded in a separate document within theproductscollection.The
returns,customers, andterritoriestables have been stored as separate collections and referenced from thesalescollection.The
calendartable was excluded as the dates are now included in thesalescollection.
Despite having ten different tables in the SQL database, we now have only five collections in our document-based database named adventureworks, encompassing the nine tables discussed above. These collections are summarized in Figure below.
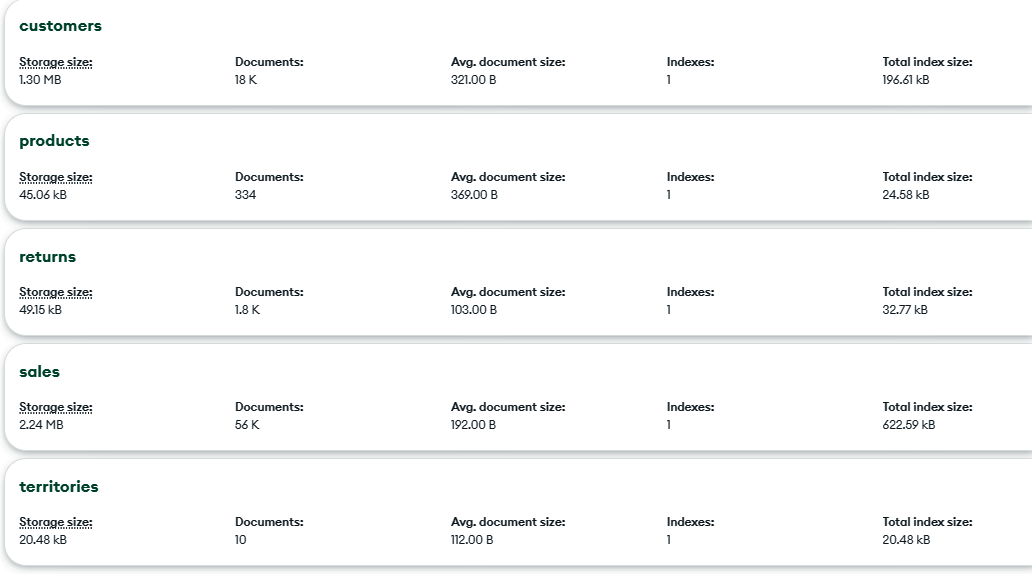
Total of five Collections
Aggregation Pipeline Code Link to heading
While SQL queries are written in Structured Query Language (SQL) for relational databases, MongoDB uses a different query language known as MongoDB Query Language (MQL).
Before obtaining any aggregation stages, we created indexes on fields that we will frequently search, sort, or group by within our collections. By creating an index on these fields, MongoDB will use the index to locate the relevant documents for the query, resulting in faster query execution times. As we are using similar queries to those in the SQL project, these fields are equivalent to Primary Keys.
Next, we proceed to build the aggregation pipelines. The aggregation framework in MongoDB provides a powerful way to perform operations such as filtering, grouping, and transforming data.
Aggregation Pipeline Examples Link to heading
Question One: Find all the products profit and identify them by their names in ascending order
adventureworks.products.aggregate([
{
$project: {
ProductName: 1,
ProductCost: 1,
ProductPrice: 1,
Profit: {
$subtract: [
"$ProductPrice",
"$ProductCost",
],
},
},
},
{
$sort: {
Profit: -1,
},
},
])

Question Two: List all the customers that their annual income is less than 20,000 and bought products in 2015.
adventureworks.sales.aggregate([
{
$lookup: {
from: "products",
localField: "ProductKey",
foreignField: "ProductKey",
as: "product_info",
},
},
{
$unwind: "$product_info",
},
{
$lookup: {
from: "customers",
localField: "CustomerKey",
foreignField: "CustomerKey",
as: "customer_info",
},
},
{
$unwind: "$customer_info",
},
{
$match: {
"customer_info.AnnualIncome": {
$lt: 20000,
},
},
},
{
$addFields: {
OrderDate: {
$toDate: "$OrderDate",
},
},
},
{
$project: {
FirstName: "$customer_info.FirstName",
LastName: "$customer_info.LastName",
AnnualIncome: "$customer_info.AnnualIncome",
ProductName: "$product_info.ProductName",
Year: {
$year: "$OrderDate",
},
},
},
])

Question Three: List all customers and their order quantities in the year 2017
adventureworks.sales.aggregate([
{
$lookup: {
from: "customers",
localField: "CustomerKey",
foreignField: "CustomerKey",
as: "customer_info",
},
},
{
$lookup: {
from: "products",
localField: "ProductKey",
foreignField: "ProductKey",
as: "product_info",
},
},
{
$unwind: "$customer_info",
},
{
$unwind: "$product_info",
},
{
$addFields: {
OrderDate: {
$toDate: "$OrderDate",
},
},
},
{
$match: {
OrderDate: {
$gte: ISODate("2017-01-01"),
$lt: ISODate("2018-01-01"),
},
},
},
{
$group: {
_id: "$customer_info.CustomerKey",
FirstName: {
$first: "$customer_info.FirstName",
},
LastName: {
$first: "$customer_info.LastName",
},
ProductName: {
$first: "$product_info.ProductName",
},
OrderQuantity: {
$sum: "$OrderQuantity",
},
OrderDate: {
$first: "$OrderDate",
},
},
},
{ $sort: { OrderQuantity: -1 } },
{
$project: {
FirstName: 1,
LastName: 1,
ProductName: 1,
OrderQuantity: 1,
Year: {
$year: "$OrderDate",
},
_id: 0,
},
},
])

Question Four: Count the products that purchased the same item in all years.
adventureworks.sales.aggregate([
{
$lookup: {
from: "customers",
localField: "CustomerKey",
foreignField: "CustomerKey",
as: "customer_info",
},
},
{
$lookup: {
from: "products",
localField: "ProductKey",
foreignField: "ProductKey",
as: "product_info",
},
},
{
$unwind: "$customer_info",
},
{
$unwind: "$product_info",
},
{
$group: {
_id: "$product_info.ProductName",
quantity_sold: {
$sum: "$OrderQuantity",
},
},
},
{
$project: {
_id: 0,
ProductName: "$_id",
quantity_sold: 1,
},
},
{
$sort: {
quantity_sold: -1,
},
},
])

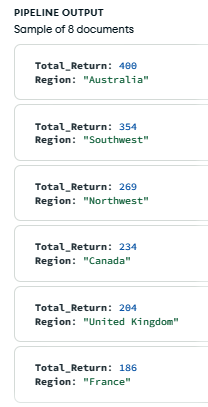
Question Five: Count the returned products group by region.
adventureworks.returns.aggregate([
{
$lookup: {
from: "territories",
localField: "TerritoryKey",
foreignField: "TerritoryKey",
as: "territory_info",
},
},
{
$unwind: "$territory_info",
},
{
$group: {
_id: "$territory_info.Region",
Total_Return: {
$sum: 1,
},
},
},
{
$sort: {
Total_Return: -1,
},
},
{
$project: {
Total_Return: 1,
Region: "$_id",
_id: 0,
},
},
])
Question Six: Find out the profit of the top 5 products for 2017.
adventureworks.sales.aggregate([
{
$addFields: {
OrderDate: {
$toDate: "$OrderDate",
},
},
},
{
$match: {
OrderDate: {
$gte: Date("2017-01-01"),
$lt: Date("2018-01-01"),
},
},
},
{
$lookup: {
from: "products",
localField: "ProductKey",
foreignField: "ProductKey",
as: "product_info",
},
},
{
$unwind: "$product_info",
},
{
$addFields: {
Profit: {
$subtract: [
"$product_info.ProductPrice",
"$product_info.ProductCost",
],
},
},
},
{
$project: {
ProductKey: "$product_info.ProductKey",
ProductName: "$product_info.ProductName",
ProductCost: "$product_info.ProductCost",
ProductPrice: "$product_info.ProductPrice",
Profit: 1,
Year: {
$year: "$OrderDate",
},
_id: 0,
},
},
{
$limit: 5,
},
])

Question Seven: Find the total returns in each year (2015, 2016, 2017)
adventureworks.returns.aggregate([
{
$addFields: {
ReturnDate: {
$toDate: "$ReturnDate",
},
},
},
{
$facet: {
year_2015: [
{
$match: {
ReturnDate: {
$gte: new Date("2015-01-01"),
$lte: new Date("2015-12-31"),
},
},
},
{
$group: {
_id: null,
Total_Returns: {
$sum: "$ReturnQuantity",
},
},
},
{
$project: {
Year: {
$literal: "2015",
},
Total_Returns: 1,
_id: 0,
},
},
],
year_2016: [
{
$match: {
ReturnDate: {
$gte: new Date("2016-01-01"),
$lte: new Date("2016-12-31"),
},
},
},
{
$group: {
_id: null,
Total_Returns: {
$sum: "$ReturnQuantity",
},
},
},
{
$project: {
Year: {
$literal: "2016",
},
Total_Returns: 1,
_id: 0,
},
},
],
year_2017: [
{
$match: {
ReturnDate: {
$gte: new Date("2017-01-01"),
$lte: new Date("2017-12-31"),
},
},
},
{
$group: {
_id: null,
Total_Returns: {
$sum: "$ReturnQuantity",
},
},
},
{
$project: {
Year: {
$literal: "2017",
},
Total_Returns: 1,
_id: 0,
},
},
],
},
},
{
$project: {
results: {
$concatArrays: [
"$year_2015",
"$year_2016",
"$year_2017",
],
},
},
},
{
$unwind: "$results",
},
{
$replaceRoot: {
newRoot: "$results",
},
},
])

Data-Models Discussion Link to heading
Relational data models, such as MySQL Workbench, are excellent for storing structured and related data, where data is organized into tables with relationships defined between them. They offer several advantages:
- Enforcing Data Integrity and Consistency: Foreign keys ensure that relationships between tables remain consistent.
- Complex Queries and Transactions: SQL allows for complex querying and transactional operations.
On the other hand, document-based data models, such as MongoDB Compass, store data in a semi-structured or unstructured format, in the form of documents (key-value pairs), which can be nested and embedded. These data models provide flexibility and scalability:
- Flexible Schema: They can store any kind of data without requiring a fixed schema beforehand.
- Handling Large Amounts of Unstructured Data: They are designed to efficiently handle large volumes of diverse data.
When deciding which model to use, it’s important to consider the specific needs of the case study. In our case, the dataset Adventure Works is highly structured, with well-defined relationships. Thus, a relational SQL data model might be a better choice for this particular dataset.
Summary Link to heading
In summary, the choice between a relational and a document-based data model should be based on the specific needs of the case study, and the strengths and limitations of each model should be taken into account. Relational data model is advisable to dataset’s that are structured and well defined relationships same to this case study, while data that is semi-structured or unstructured, and requires scalability and flexibility, a document-based data model may be a better option.